안녕하세요. 보랏입니다.
오늘은 딥러닝의 전이학습을 사용해서 모델의 정확성을 높이는
자율 시간을 가졌습니다.
그래서 오늘의 복습은 전이학습에 대한 내용과 실제 진행했던 모델 생성 과정을 복습하도록 하겠습니다.
복습 시작하겠습니다.
1. ANN, CNN, DNN, RNN
ANN (Arifical Neural Network) 인공신경망
- 사람의 신경망 원리와 구조를 모방하여 만든 기계학습 프로그램
- 입력데이터(input data), 가중치(weight), 출력데이터(output data)
- 인공신경망은 시냅스의 결합으로 네트워크를 형성한 인공뉴런이 학습을 통해 시냅스의 결합 세기를 변화 시켜 문제해결능력을 가지는 모델 전반을 의미
- 다수의 입력 데이터를 받는 입력층, 데이터의 출력을 나타내는 출력층, 입력과 출력층 사이에 존재하는 레이어들(은닉층)이 존재
ANN문제점
- 학습 과정에서 최적값을 찾기 어렵고, 과적합 문제가 존재
DNN (Deep Neural Network)
- ANN 기법의 여러 문제를 해결하기 위해 모델 내의 은닉층을 많이 늘려서 학습의 결과를 향상시키는 방법
- 은닉층이 2개 이상 보유
- 컴퓨터가 스스로 분류레이블을 만들어내고 공간을 왜곡하고 데이터를 구분짓는 과정을 반복하여 최적의 구분선을 도출해냄. 많은 데이터와 반복학습, 사전학습 그리고 오류역전파 기법을 통해 널리 사용 중.
CNN (Convolution Neural Network) 합성곱신경망
- CNN은 데이터의 특징을 추출하여 특징들의 패턴을 파악하는 구조 기존 방식은 데이터에서 정보를 추출해 학습이 이뤄짐
- CNN 알고리즘은 Convolution 과정과 Pooling과정을 통해 진행됨.
- Convolution Layer와 Pooling Layer를 복합적으로 구성하여 알고리즘을 만드는 것.
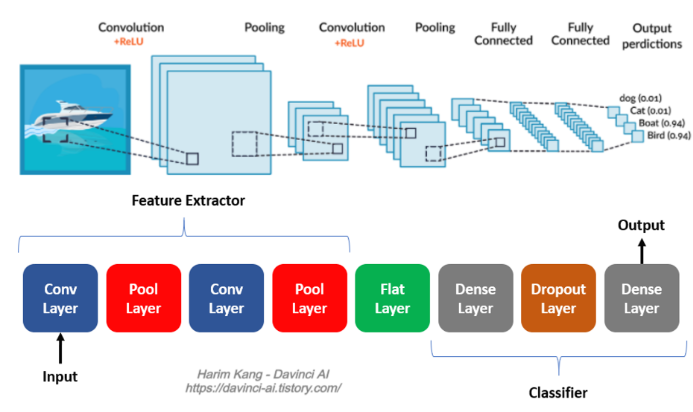
Convolution
- 데이터의 특징을 추출하는 과정
- 데이터의 각 성분의 인접 성분들을 조사해 특징을 파악하고 파악한 특징을 한 장으로 도출시키는 과정
- 여기서 도출된 정보를 Convolution Layer라고 부름 -> 이 과정은 하나의 압축 과정이며 파라미터의 개수를 효과적으로 줄여줌

Pooling
- Convolution 과정을 거친 Layer의 사이즈를 줄여주는 과정. 단순히 데이터의 사이즈를 줄여주고 노이즈를 상쇄시키는 미세한 부분에서 일관적인 특징을 제공

Flatten
- CNN에서 Convolution 와 Pooling Layer를 반복적으로 거치면 주요 특징만 추출됨
- 추출된 주요 특징은 2차원 데이터로 이루어져 있지만 Dense와 같이 분류를 위한 학습 레이어에서는 1차원 데이터로 학습이 되어야한다.
- 이 때, Flatten Layer는 2차원 데이터를 1차원 데이터로 바꾸는 역할의 Layer
tf.keras.layers.Flatten()
Dropout Layer
- 네트워크가 과적합되는 경우를 방지하기 위해 Layer
- 학습 과정에서 무작위로 뉴런의 집합을 제거하는 것이 과적합을 막는다는 아이디어에서 등장
- 무작위로 부분적인 뉴런을 제거하는 방식
- 과적합 방지를 위한 역할
- rate : 제외할 뉴런의 비율을 나타내는 값
tf.keras.layers.Dropout(rate=0.2)
2. 전이학습
- 이미지 분류 문제를 해결하는데 사용했던 네트워크 (DNN)를 다룬 데이터셋 혹은 다른 문제 (task)에 적용시켜 푸는 학습 방법
- 기계의 시각적 이해를 목표로 하는 컴퓨터 비전의 영적에서 전이 학습으로 수행된 모델들이 높은 성능을 보이고 있어 가장 많이 사용
전이학습의 정확도가 높은 이유
- 네트워크가 다양한 이미지의 보편적인 특징 혹은 피처(feature)들을 학습하여 정확도가 높음
- 일반적으로 네트워크가 깊어질수록 서로 다른 종류의 피처들을 학습
- 낮은 층에서 학습하는 피처 : low-level features (이미지의 색, 경계)
- 깊은 층에서 학습하는 피처 : high-level features (객체의 패턴, 형태)

사용방법
- imagenet과 같은 대량의 데이터셋으로 이미 학습이 되어있는 모델을 사용
- 사전에 학습된 모델이라고 부름
3. 딥러닝 모델링
from mpl_toolkits.mplot3d import Axes3D
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt # plotting
import numpy as np # linear algebra
import os # accessing directory structure
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# cifar10 데이터셋 로드
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
# shape 확인
print(X_train.shape) --> (50000, 32, 32, 3)
print(y_train.shape) --> (50000, 1)
print(X_test.shape) --> (10000, 32, 32, 3)
print(y_test.shape) --> (10000, 1)
# 1. 데이터 전처리 - 실수형으로 정규화
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
X_train = X_train.astype('float32') / 255.0
X_test = X_test.astype('float32') / 255.0
y_train = tf.keras.utils.to_categorical(y_train)
y_test = tf.keras.utils.to_categorical(y_test)
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(128, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.6),
tf.keras.layers.Dense(10, activation='softmax')
])
# 3. 모델 컴파일
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 4. 모델 학습
model.fit(X_train, y_train, epochs=10, batch_size=128, validation_data=(X_test, y_test))
# 5. 모델 평가
test_loss, test_acc = model.evaluate(X_test, y_test)
print('Test accuracy:', test_acc)
- 제가 작성한 딥러닝 모델은 레이어 3개층에 벡터는 32, 3, 3크기의 텐서로 설정해서 2배씩 늘어나게 해서 128,3,3으로 설정하였습니다.
- relu 활성화 함수를 진행하여 softmax 다중 분류 함수를 사용
- batch_size : 128
- dropout : 0.6
- 정확도는 0.7이 나왔는데 한 번 더 레이어 증가하던가 dropout을 높여서 다시 돌려봐야 될 것 같습니다.
이렇게 오늘 복습 마무리하겠습니다.
감사합니다.
'DB 공부하기' 카테고리의 다른 글
| 230424_DB복습 (0) | 2023.04.24 |
|---|---|
| 230420_DB복습 (0) | 2023.04.20 |
| 230418_DB복습 (0) | 2023.04.18 |
| 230417_DB복습 (0) | 2023.04.17 |
| 230411_DB복습 (0) | 2023.04.11 |



