안녕하세요. 보랏입니다.
이번주가 새로 시작되어 바로 복습 내용 올리도록 하겠습니다.
오늘은 언더 샘플링, 오버샘플링에 대한 개념과
이 개념을 알아보기 위해 Kaggle에서 데이터 자료를 가져와 분석을 진행하였으며,
Django에서 DB설정 및 홈페이지 제작을 배웠습니다.
바로 복습 시작하겠습니다.
1. 언더샘플링(undersampling) 과 오버샘플링(oversampling)
- 레이블이 불균형한 분포를 가진 데이터 셋을 학습시킬 때 예측 성능의 문제가 발생할 수 있는데, 이는 이상 레이블을 가지는 데이터 건수가 정상 레이블을 가진 데이터 건수에 비해 너무 적어 발생
- 즉 이상 레이블을 가지는 데이터 건수는 매우 적기 때문에 제대로 다양한 유형을 학습하지 못하는 반면에 정상 레이블을 가지는 데이터 건수는 매우 많기 때문에 일방적으로 정상 레이블로 치우친 학습을 수행해 제대로 된 이상 데이터 검출이 어려워지기 쉬움
- 지도학습에서 극도로 불균형한 레이블 값 분포로 인한 문제점을 해결하기 위해서는 적절한 학습 데이터를 확보하는 방안이 필요하며, 대표적으로 오버샘플링과 언더샘플링 방법 존재

2. 언더샘플링
- 많은 데이터 셋을 적은 데이터 셋 수준으로 감소시키는 방식
- 즉 정상 레이블을 가진 데이터가 10,000건이 있고 이상 레이블을 가진 데이터가 100건 있다고 하면 정상 레이블의 건수를 100건으로 줄이는 방식
- 레이블의 균형은 맞출 수 있지만 너무 많은 정상 레이블 데이터를 감소시키기 때문에 정상 레이블의 경우 오히려 제대로 된 학습을 수행할 수 없다는 단점이 있어 잘 적용하지 않는 방법임
3. 오버샘플링
- 이상 데이터와 같이 적은 데이터 셋을 증식하여 학습을 위한 충분한 데이터를 확보하는 방법
- 동일한 데이터를 단순히 증식하는 방법은 과적합(overfitting)이 되기 때문에 의미가 없으므로 원본 데이터의 피처 값들을 아주 약간만 변경하여 증식합니다.
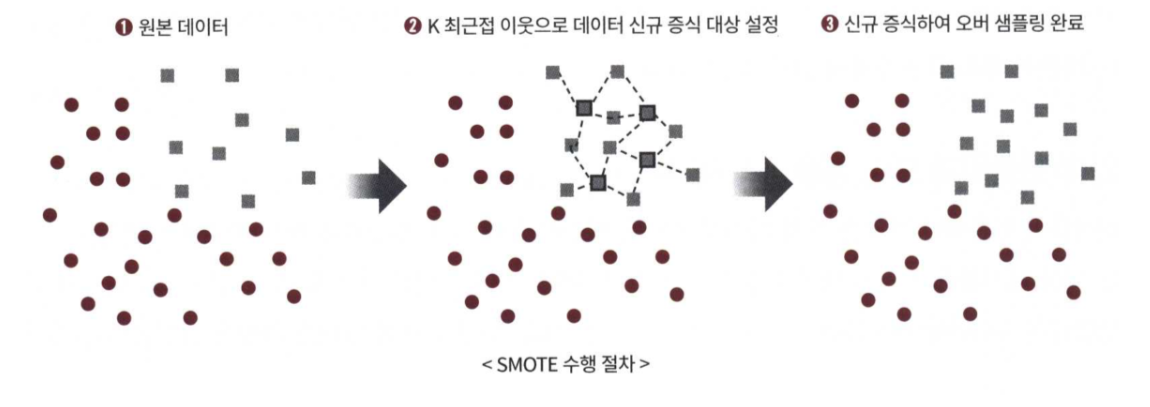
- 대표적인 방법으로 SMOTE(Synthetic Minority Over-samling Technique) 방법이 있습니다.
- SMOTE는 적은 데이터 셋에 있는 개별 데이터들의 K-NN을 찾아서 이 데이터와 K개 이웃들의 차이를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터들을 생성하는 방식
4. Kaggle 데이터 활용 모델 평가 (https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud)
Credit Card Fraud Detection
Anonymized credit card transactions labeled as fraudulent or genuine
www.kaggle.com
- Kaggle의 신용카드 데이터 셋
- 신용카드 사기 검출 분류 실습을 진행
- 해당 데이터 셋의 레이블인 Class 속성은 매우 불균형한 분포를 가지고 있다.
- Class는 0과 1로 분류되는데 0이 사기 아닌 정상적인 신용카드 트랜잭션 데이터, 1은 신용카드 사기 트랜잭션을 의미
- 일반적으로 사기 검출(Fraud Detection)이나 이상 검출(Anomaly Detection)과 같은 데이터 셋은 이처럼 레이블 값이 극도로 불균형한 분포를 가지고 있을 것이다.
card_df = pd.read_csv("./creditcard.csv")
card_df.head(3)
card_df.Class.value_counts(normalize=True)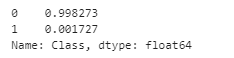
from sklearn.model_selection import train_test_split
# 인자로 입력받은 DataFrame을 복사 한 뒤 Time 컬럼만 삭제하고 복사된 DataFrame 반환
def get_preprocessed_df(df=None):
df_copy = df.copy()
df_copy.drop('Time', axis=1, inplace=True)
return df_copy
# 사전 데이터 가공 후 학습과 테스트 데이터 세트를 반환하는 함수.
def get_train_test_dataset(df=None):
# 인자로 입력된 DataFrame의 사전 데이터 가공이 완료된 복사 DataFrame 반환
df_copy = get_preprocessed_df(df)
# DataFrame의 맨 마지막 컬럼이 레이블, 나머지는 피처들
X_features = df_copy.iloc[:, :-1]
y_target = df_copy.iloc[:, -1]
# train_test_split( )으로 학습과 테스트 데이터 분할. stratify=y_target으로 Stratified 기반 분할
X_train, X_test, y_train, y_test = \
train_test_split(X_features, y_target, test_size=0.3, random_state=0, stratify=y_target)
# 학습과 테스트 데이터 세트 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('학습 데이터 레이블 값 비율')
print(y_train.value_counts()/y_train.shape[0] * 100)
print('테스트 데이터 레이블 값 비율')
print(y_test.value_counts()/y_test.shape[0] * 100)
- 로지스틱 모델 생성
#### 로지스틱 모델 생성
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression()
lr_clf.fit(X_train, y_train)
lr_pred = lr_clf.predict(X_test)
lr_pred_proba = lr_clf.predict_proba(X_test)[:, 1]
# 3장에서 사용한 get_clf_eval() 함수를 이용하여 평가 수행.
get_clf_eval(y_test, lr_pred, lr_pred_proba)
- lightgbm 모델 생성
# 인자로 사이킷런의 Estimator객체와, 학습/테스트 데이터 세트를 입력 받아서 학습/예측/평가 수행.
def get_model_train_eval(model, ftr_train=None, ftr_test=None, tgt_train=None, tgt_test=None):
model.fit(ftr_train, tgt_train)
pred = model.predict(ftr_test)
pred_proba = model.predict_proba(ftr_test)[:, 1]
get_clf_eval(tgt_test, pred, pred_proba)
from lightgbm import LGBMClassifier
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_averㅁage=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
- 데이터 분포도 변환 후 모델 학습 / 예측 / 평가
- 왜곡된 분포도를 가지는 데이터를 전처리 진행
- 로지스틱 회귀는 선형 모델이기 때문에 변수들의 정규 분포 형태를 유지하는 것을 선호
- Amount 변수는 신용 카드 사용 금액으로 정상/사기 트랜잭션을 결정하는데 매우 중요한 속성일 가능성이 있음
import seaborn as sns
plt.figure(figsize=(8, 4))
plt.xticks(range(0, 30000, 1000), rotation=60)
sns.histplot(card_df['Amount'], bins=100, kde=True)
plt.show()
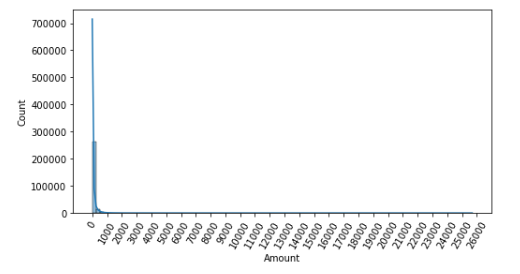
- 카드 사용금액이 1000불 이하인 데이터가 대부분이며, 27,000불까지 드물지만 많은 금액을 사용한 경우가 발생하면서 꼬리가 긴 형태의 분포 곡선을 가지고 있음
- 이 후 데이터 Amount를 표준 정규 분포 형태로 변환한 뒤에 로지스틱 회귀의 예측 성능을 측정
## 데이터 정규화
from sklearn.preprocessing import StandardScaler
# 사이킷런의 StandardScaler를 이용하여 정규분포 형태로 Amount 피처값 변환하는 로직으로 수정.
def get_preprocessed_df(df=None):
df_copy = df.copy()
scaler = StandardScaler()
amount_n = scaler.fit_transform(df_copy['Amount'].values.reshape(-1, 1))
# 변환된 Amount를 Amount_Scaled로 피처명 변경후 DataFrame맨 앞 컬럼으로 입력
df_copy.insert(0, 'Amount_Scaled', amount_n)
# 기존 Time, Amount 피처 삭제
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
return df_copy
## 모델 학습 및 평가
# Amount를 정규분포 형태로 변환 후 로지스틱 회귀 및 LightGBM 수행.
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
lr_clf = LogisticRegression()
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
lgbm_clf = LGBMClassifier(n_estimators=1000, num_leaves=64, n_jobs=-1, boost_from_average=False)
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
- 데이터 분포도가 왜곡되어 있어 '로그 변환'을 통해 원래 값을 log값으로 변환해 원래 큰 값을 상대적으로 작은 값으로 변환하기 때문에 데이터 분포도의 왜곡을 상당 수준 개선 가능
## 로그변환
def get_preprocessed_df(df=None):
df_copy = df.copy()
# 넘파이의 log1p( )를 이용하여 Amount를 로그 변환
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
return df_copy
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
- 이상치 데이터 제거 후 모델 학습 / 예측 / 평가
- 어떤 피처의 이상치 데이터를 검출할 것인지 선택하기 위해서 상관성이 높은 피처를 도출
import seaborn as sns
plt.figure(figsize=(9, 9))
corr = card_df.corr()
sns.heatmap(corr, cmap='RdBu')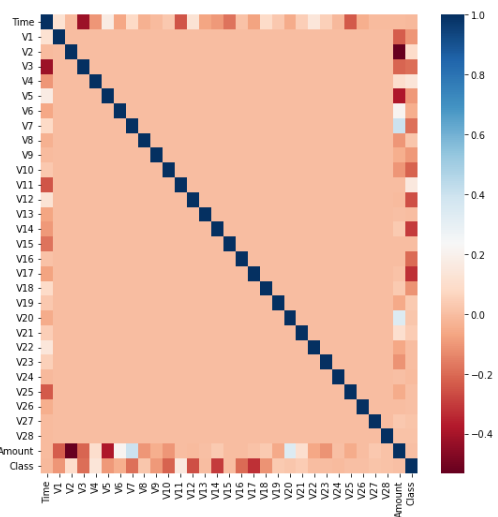
- 많은 변수(피처)가 있을 경우 이들 중 결정값(y값, 레이블)과 가장 상관성이 높은 변수들을 시각화함
- RdBu로 설정하여 양의 상관관계가 높을수록 색깔이 진한 파란색에 가까우며, 음의 상관관계가 높을수록 진한 빨간색에 가깝게 표현.
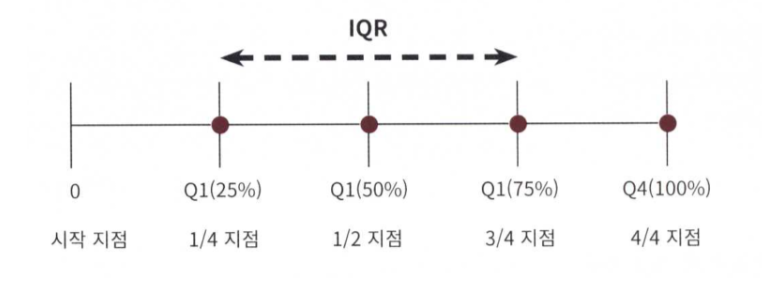
- IQR를 이용한 이상치 제거
- IQR(Inter Quantile Range) 방식을 적용하여 이상치를 제거
- IQR은 사분위 값의 편차를 이용하는 기법으로 흔히 박스 플롯 방식으로 시각화할 수 있음

import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
# fraud에 해당하는 column 데이터만 추출, 1/4 분위와 3/4 분위 지점을 np.percentile로 구함.
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
# IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함.
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
# 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환.
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_index
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
print('이상치 데이터 인덱스:', outlier_index)
# get_processed_df( )를 로그 변환 후 V14 피처의 이상치 데이터를 삭제하는 로직으로 변경.
def get_preprocessed_df(df=None):
df_copy = df.copy()
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
# 이상치 데이터 삭제하는 로직 추가
outlier_index = get_outlier(df=df_copy, column='V14', weight=1.5)
df_copy.drop(outlier_index, axis=0, inplace=True)
return df_copy
X_train, X_test, y_train, y_test = get_train_test_dataset(card_df)
print('### 로지스틱 회귀 예측 성능 ###')
get_model_train_eval(lr_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
print('### LightGBM 예측 성능 ###')
get_model_train_eval(lgbm_clf, ftr_train=X_train, ftr_test=X_test, tgt_train=y_train, tgt_test=y_test)
5. django DB 및 페이지 구축
- app 만들기 (pybo 폴더 생성 후 pybo 폴더에서 아래 명령어 실행)
django-admin startapp pybo- base.py에 app 등록
# base.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'pybo.apps.PyboConfig'
]- mysite 폴더 밑에 urls.py에 views.index 추가
# urls.py
from django.contrib import admin
from django.urls import path
from pybo import views
urlpatterns = [
path('admin/', admin.site.urls),
path('pybo/', views.index)
]- pybo폴더 view.py에 request를 파라미터로 받아 실행하는 함수 생성

- 웹 브라우저에 "http://127.0.0.1/pybo/" 입력

- urls.py에 pybo앱에 관련한 것들은 pybo앱 디렉터리 하위에 위치해야 하나, pybo와 관련된 URL매핑을 추가할 때마다 config/urls.py파일을 수정해야 함
- config의 urls.py파일은 앱이 아닌 프로젝트 성격의 파일이므로 이곳에는 프로젝트 성격의 URL매핑만 추가 필요
- path('pybo/', views.index) --> path('pybo/', include('pybo.urls'))
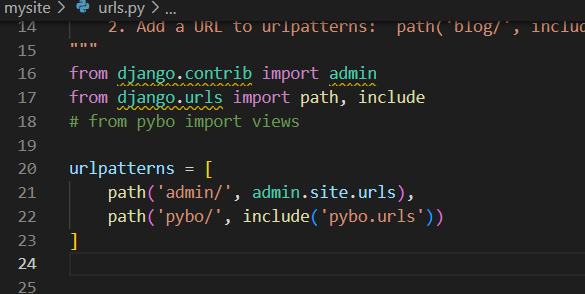
- pybo/로 시작하는 페이지를 요청하면 이제 pybo/urls.py 파일의 매핑 정보를 읽어서 처리하라는 의미
- 따라서 이제 pybo/로 시작하는 URL을 추가해야 할 때, config/urls.py 파일을 수정할 필요없이 pybo/urls.py파일만 수정하면 됨
- 이제 pybo폴더에 pybo/urls.py 생성 후 아래 코드 입력


- path(' ', views.index)처럼 pybo/가 생략된 ' '이 사용
- config/urls.py파일에서 이미 pybo/로 시작하는 URL이 pybo/urls.py 파일과 먼저 매핑됨
- pybo/ URL은 다음처럼 config/urls.py 파일에 매핑된 pybo/ 와 pybo/urls.py 파일에 매핑된 '' 이 더해져 pybo/가 된다.
- 컨테이너 재가동 : docker restart pybo
- pybo폴더 아래 models.py 파일 생성 후 아래 코드 입력(DB생성)
from django.db import models
class Question(models.Model):
subject = models.CharField(max_length=200)
content = models.TextField()
create_date = models.DateTimeField()
class Answer(models.Model):
question = models.ForeignKey(Question, on_delete=models.CASCADE)
content = models.TextField()
create_date = models.DateTimeField()- SQL(DBMS프로그램)로 아래 쿼리로 database 생성 : create database pybo
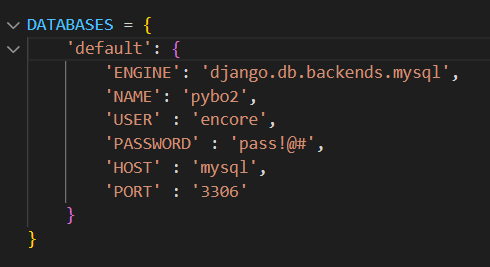
- local.py 와 prod.py에서 DB설정을 pybo 수정 후 models.py 만든 테이블을 실제 테이블로 이관
python manage.py makemigrations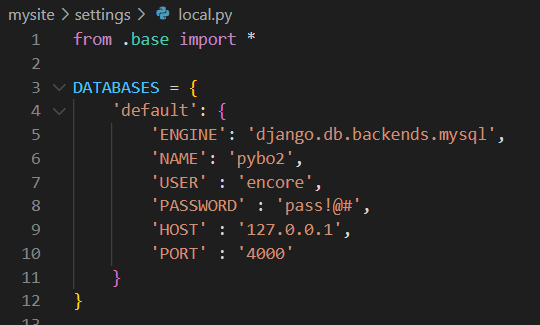
- 터미널에 python manage.py migrate 입력
- 의미 : migration적용 명령어, 실제 DB에 변경사항을 적용하는 명령어
- python shell 실행 및 django-extensions, ipython, jupyter 설치
python manage.py shell
pip install django-extensions
pip install ipython
pip install jupyter- local.py에 코드 추가 : INSTALLED_APPS.append("django_extensions")
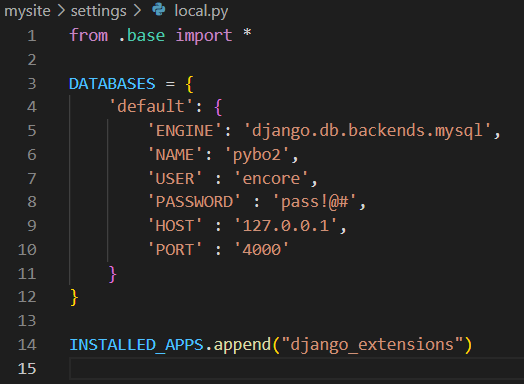
- 터미널에 python manage.py shell_plus --notebook 입력 후 url 실행




- django 환경에서도 데이터값이 한글로 표현되기 위해 models.py에 함수 추가 필요
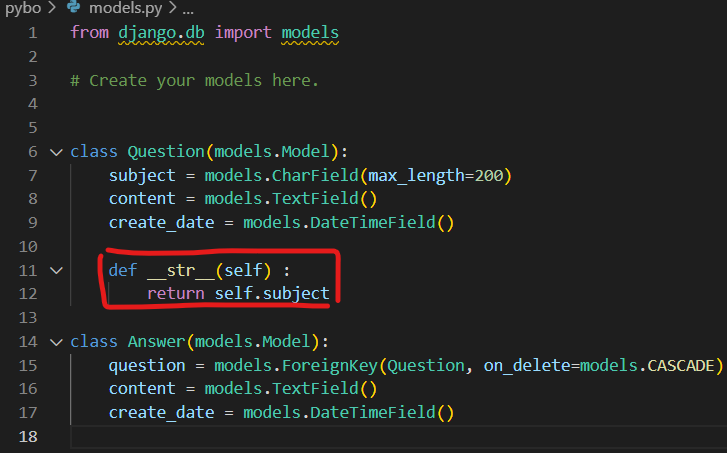

- 이제 Answer 클래스(DB)에도 특정 ID 값마다 대응되는 데이터 생성을 진행


이렇게 오늘 하루도 복습 마무리 하도록 하겠습니다.
감사합니다.
'DB 공부하기' 카테고리의 다른 글
| 230417_DB복습 (0) | 2023.04.17 |
|---|---|
| 230411_DB복습 (0) | 2023.04.11 |
| 230406_DB복습 (0) | 2023.04.07 |
| 230405_DB복습 (0) | 2023.04.05 |
| 230404_DB복습 (0) | 2023.04.04 |



